Rails アンチパターン - 覗き見モデルクラス(Voyeuristic Models)
はじめに
引き続きRails AntiPatternsという本を読んでいます。
https://www.amazon.co.jp/dp/B004C04QE0/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1
前回は2 Domain Modelingの1つめ「Authorization Astronaut」についてまとめました。
今回は1 Modelsの1つめ「Voyeuristic Models」についてまとめていきます。
Voyeuristic Models
Ruby on Rails、MVC、およびオブジェクト指向プログラミングが提供する構造を認識していない場合などに、オブジェクト指向の基本的な原則を破ってしまうことがあります。またActiveRecordなどの便利な機能に乗りすぎてしまう場合もあります。
ここでは、MVCとオブジェクト指向プログラミングの教えに違反するいくつかのサンプルを見ていきます。
Solution: Follow the Law of Demeter(デルメルの法則に従う)
サンプルで見ていこうと思います。以下のようなモデルがあるとします。
class Address < ApplicationRecord belongs_to :customer end class Customer < ApplicationRecord has_one :address has_many :invoices end class Invoice < ApplicationRecord belongs_to :customer end
顧客は住所を1つ、請求を複数持ちます。請求の住所行を表示するビューは、次のようになります。
<%= @invoice.customer.name %> <%= @invoice.customer.address.street %> <%= @invoice.customer.address.city %>, <%= @invoice.customer.address.state %> <%= @invoice.customer.address.zip_code %>
適切なカプセル化を考えると、@invoiceはcustomerを経由してaddressにアクセスするべきではありません。たとえば、顧客が請求先住所と配送先住所の両方を持つようにアプリケーションを変更すると、これらのオブジェクトを通過して通りを取得するコード内のすべての場所が壊れ、変更する必要があるためです。
幸いにも、ActiveRecordには、delegateというメソッドがあります。このデリゲートメソッドを使用すると、addressオブジェクトのことを知ることなく顧客の住所を表示できます。
class Address < ApplicationRecord belongs_to :customer end class Customer < ApplicationRecord has_one :address has_many :invoices delegate :street, :city, :state, :zip_code, to: :address end class Invoice < ApplicationRecord belongs_to :customer delegate :name, :street, :city, :state, :zip_code, to: :customer, prefix: true end
viewのコードは以下のようになります。
<%= @invoice.customer_name %> <%= @invoice.customer_street %> <%= @invoice.customer_city %>, <%= @invoice.customer_state %> <%= @invoice.customer_zip_code %>
これやったほうがいいとは思うのですが、関連するオブジェクトをそのまま取って出すだけなら最初のままでもいい気がします。ただ悩ましいところではある…。これちょっと修正したいときに.gsubとかviewに書いてしまう事があって、それを助長する気がしています。そしてDRYでない子0ドが生まれていくという。なので1回これに従ってみるのもいいかなと思えてきました。
Solution: Push All find() Calls into Finders on the Model(生のクエリメソッドは全てモデルに書く)
これもサンプルを見ます。
<html>
<body>
<ul>
<% User.order(:last_name).each do |user| -%>
<li><%= user.last_name %> <%= user.first_name %></li> <% end %>
</ul>
</body>
</html>
これはビューに直接sql呼び出しが書いている状態であり、重複するロジックがそれぞれの場所で生まれてしまう可能性があります。
ひとまずコントローラに移します。
class UsersController < ApplicationController def index @users = User.order(:last_name) end end
<html>
<body>
<ul>
<% @users.each do |user| -%>
<li><%= user.last_name %> <%= user.first_name %></li> <% end %>
</ul>
</body>
</html>
これでモデルのロジックはなくなりましたが、コントローラにロジックの記載が残っています。これをモデルに移します。
class User < ApplicationRecord scope :ordered, -> { order(:last_name) } end
class UsersController < ApplicationController def index @users = User.ordered end end
Solution: Keep Finders on Their Own Model (生のクエリメソッドは自身のクラスにしか書かない)
検索コールをRailsアプリケーションのコントローラレイヤーからモデル上のカスタムファインダに移動することは、メインテナンス可能なソフトウェアを作成する正しい方向への強力なステップです。しかし、一般的な間違いは、適切な責任の委任を無視して、それらの呼び出しを最も近いモデルに移動することです。
耳が痛い話だ!!!
class UsersController < ApplicationController def index @user = User.find(params[:id]) @memberships = @user.memberships.where(active: true). limit(5). order("last_active_on DESC") end end
今まで学んだことに基づいて、そのスコープチェーンをUserモデルのメソッドに徹底的に移動します。UsersControllerを扱っているので、これが最良の場所のようだと思います。
class UsersController < ApplicationController def index @user = User.find(params[:id]) @recent_active_memberships = @user.find_recent_active_memberships end end
class User < ApplicationRecord has_many :memberships def find_recent_active_memberships memberships.where(active: true). limit(5). order('last_active_on DESC') end end
これは間違いなく改善です。 しかし、もう少しすることができます。Userモデルはメンバーシップモデルの実装について、active、last_active_onというカラムのことを知ってしまっています。これは、まだメソッドを十分にプッシュしていないという手がかりです。
(途中経過を省き最終型のみ載せます)
class User < ApplicationRecord has_many :memberships def find_recent_active_memberships memberships.only_active.order_by_activity.limit(5) end end class Membership < ApplicationRecord belongs_to :user scope :only_active, where(active: true) scope :order_by_activity, order('last_active_on DESC') end
scopeにしたことによりロジックを組み合わせて使うことができます。
scopeにしたことが良いのと、limit(5)がUserモデルにあるのがすごくいい感じがしています。
このアプローチには、読みやすさとシンプルさの問題だけでなく、デメテルの法律の乱用などの短所もあります。
このアプローチを使用するかどうかは、あなた次第です。多くの高度なリファクタリングと同様に、これは簡単な答えがなく、好みにも大きくよるものです。
まとめ
正直ここまで徹底してやったことがなく、これを都度やっていくコストがどれくらいなのかわかりません。ただ、毎回コントローラに書いていってしまうと共通化、scope化するのがどんどん難しくなっていくので、ある程度の規模ではやるべきなのかなと思っています。モデル50個からとか?
とりあえず、次自分で何か書くときにはこれ徹底してみようと思います。
Rails アンチパターン - 使われない権限メソッド(Authorization Astronaut)
はじめに
最近Rails AntiPatternsという本を読んでいました。
https://www.amazon.co.jp/dp/B004C04QE0/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1
幾つかの項目を読んだ所なかなかおもしろそうだったので一冊通して読もうと思っています。
翻訳版はないので、ざっくり訳しつつ自分の感想を書いていこうと思います。
2010年に発売されたもので、サンプルコードやgem等は古いので適宜読み替える必要があります。
また、サンプルコードは一部変更して掲載しています。
Authorization Astronaut
権限ロジックは仕様に基づいて、または将来の要件を予期してプログラムされます。その結果、一般的なユーザー認証では、次のようなユーザー・モデルが作られます。
class User < ApplicationRecord has_many :user_roles has_many :roles, through: :user_roles def has_role?(role) roles.exists?(name: role) end def can_post? has_roles?(%w(admin editor associate_editor research_writer)) end def can_review_posts? has_roles?(%w(admin editor associate_editor)) end def can_edit_content? has_roles?(%w(admin editor associate_editor)) end def can_edit_post?(post) self == post.user || has_roles?(%w(admin editor associate_editor)) end end
can_*というメソッドは破滅への道です。いつ使われるかわからず、インタフェースも曖昧で一貫性がないです。今後も必要になる前から権限ロジックだけ先に追加されるようになります。 また、admin, editor等の権限名がハードコーディングされていて、変更に弱い状態です。
自分もこんな感じのをモデル見たことがあり、ああーなるほどという感じでした。モデルとコントローラを別の人で開発した場合にこんな感じになりがちな印象です。
ハードコーディングやめて定数にすればという人もいますが、本質的には変わらないと思います笑
ユーザにはロールをつけることができます。
class Role < ApplicationRecord has_many :user_roles has_many :users, through: :user_roles validates :name, uniqueness: true, presence: true def name=(value) write_attribute(:name, value.downcase) end def self.[](name) find_by(name: name.to_s) end def add_user(user) users << user end def delete_user(user) users.delete(user) end end
Roleモデルにはいくつかの問題があります。管理ユーザーがロールを追加または削除できるようにする計画はありません。 また、Role.[]というメソッドは識別子の変更を吸収するのに使われるかもしれませんが、その意図で書かれていないため、機能しません。どこでも使われない可能性もあります。
add_user、delete_userも良いインタフェースではありません。
あるあるだw
要するに、これら2つのモデルは独立して書かれました。アプリケーションの仕様が固まる前に、将来何が必要になるかを見越して書かれています。これは認証ロジック実装でかなり発生するようです。仕様を固めている間に、認証ロジックが開発者が事前に開始できるものとして認識されるためです。
これは誤った仮定で、過剰に設計されたコードにつながり、あいまいで矛盾したインターフェイスを提供し、正しく使用されないか、まったく使用されなくなってしまいます。
とはいえ、チームの文化とかいろんな要因で、やりたいことを理解する前(仕様が固まる前とは違う)にロジック部分だけ作ってしまい、こうゆうコードが生まれるのはたまに見かけます。
Solution: Simplify with Simple Flags
前のセクションで説明した複雑さの問題に対処するために、次のようにモデルをリファクタリングすることができます。
class User < ApplicationRecord end
class AddColumnToUsers < ActiveRecord::Migration[5.1] def change add_column :users, :admin, :boolean, null: false, default: false add_column :users, :editor, :boolean, null: false, default: false add_column :users, :writer, :boolean, null: false, default: false end end
https://github.com/waterlow/authorization_astronaut/pull/2
これによって
Roleモデルが削除でき、Userモデルにはadmin?、editor?などのメソッドが使えるようになります。フレームワークの機能をを効果的につかい、「コードが無い」という一番きれいな状態になります。今後1つ2つのロール追加くらいならばこの方法でも問題は無いでしょう。
なかなか衝撃的でした。3つあったテーブルを一つにしてしまって、しかもUserモデルには何も書かないというシンプルさ…。仕事だとこう言う選択は非常に勇気が要りますが、シンプルさを保つ事ができる非常に良い方法だと感じました。
それ以上にロールが追加される場合は、テーブルを増やしましょう。ただし、多対多用の中間テーブルは作らず、
has_manyで完結させます。
class User < ApplicationRecord has_many :roles Role::TYPES.each do |role_type| define_method("#{role_type}?") do roles.exists?(name: role_type) end end end
class Role < ApplicationRecord TYPES = %w(admin editor writer guest) validates :name, inclusion: { in: TYPES } end
https://github.com/waterlow/authorization_astronaut/pull/3
これは、不必要なコードを排除し、過剰に設計されていないため、ユーザーの役割を扱う方法について疑問のない一貫したインターフェイスを提供するため、成功しています。
やっぱり前者のadmin?メソッドにこだわっていて、Railsの機能が提供してくれるものが一番シンプルだという考え方ですかね。私もこの辺は同意です。自前で書くよりはよっぽどいい。あと、DBの外部キー制約が使えなさそうだけど、モデルでバリデーション入れてるからいいよねという気持ちだろうと思います。
ここで概説した概念は、ユーザーの役割にのみ適用されるものではありません。また、アプリケーションドメインをモデル化し、モデルによって提供されるインタフェースを定義するときに、他の多くの状況にも適用できます。以下の簡単なガイドラインは、オーバーエンジニアリングを止め、定義されていない仕様とアプリケーションの変更の両方に直面する簡単なインターフェイスを提供するのに役立ちます。
•コードを書くときにアプリケーションの要件を超えて構築しないでください。
•具体的な要件がない場合は、コードを記述しないでください。
•すぐにモデルを作ろうとしないでください。付加的なモデルの追加を避けるために、ブーリアンや非正規化などの単純な方法がよく使用されます。
•データの追加、削除、または管理のためのユーザーインターフェイスがない場合、モデルは必要ありません。 ハッシュまたは可能な値の配列で作成された非正規化列で問題ありません。
最後のはシリアライズのことをいっているのかなと思います。UIがない場合はモデル作らなくてもシリアライズで問題ないという考えは、以前ActiveRecord serialize / store の甘い誘惑を断ち切ろうという記事を読んで以来やらないほうがいいと思っていましたが、認可のようなアプリのメイン機能とは異なる場面では使ってもいいかなと思いました。
また、UIがない場合にモデルを追加しないという決断は驚きでした。
個人的な意見としては、空のモデルを作ってもいいかなとは思ったのですが、モデルを作ってしまう時点で将来の要求とはずれてしまうかもしれませんし、やはりモデルを作らないで済むのが一番拡張性の高い状態かなと思いました。
まとめ
仕事でこうゆうリファクタリングをぶっこんでいくのはなかなか難しそうですが、必要になるまで作らないという視点は常に持っておきたいです。
【LT】表参道.rbでActiveRecordのテーブル名の決め方等について発表してきました。
はじめに
ActiveJobのキュー名の設定をどうするかを考えていた過程で、ActiveRecordのテーブル名の決め方を調べていました。色々と面白いところがあったので表参道.rbで発表してきました。(ただのテーブル名あてゲーです。)
基本はシンプルに「親のテーブル名を見に行く」だけだった

こんな風にabstract_classが複数入っていると難しく見えがちですが、AdminUserが読まれたときにテーブル名がadmin_usersになり、そのサブクラスのtable_nameは、指定しない場合はすべてadmin_usersとなります。
abstract_classはレコードを作れないということだけで、テーブル名の決め方には関係ありませんでした。
まとめ
普段深く知らないまま使っている機能について、ソースを読んで理解を固めていくのは非常にいい感じでした。
【LT】encrypted secretsについて社内LT大会でしゃべってきました。
はじめに
Rails5.1で導入されたencrypted secretsについて所属する会社の社内LT大会で発表してきました。
0323社内LT大会 from Akira Ohta
内容
5分だったので大したことは書いていませんが、機能の説明以外はstaging問題やメインです。
所感(使えそう?)
staging問題について
詳細
- デフォルトではkeyと暗号化ymlは一組しか作られない。
Rails.env == 'staging' # => trueでも本番と同じkeyを使うことになる。- ステージングのkeyが流出するだけで本番のkey流出となってしまう。
解決策
- secrets.#{Rails.env}.yml.encとそれに対応するkeyを別で持っておく。
- 例えばsecrets.staging.yml.enc, secrets.production.yml.enc(rails secrets:setup, rails secrets:editしたらリネームする)
- デプロイ時にln -sする。
まとめ
- なにはともあれ設定ファイルコミットできるのは良い!
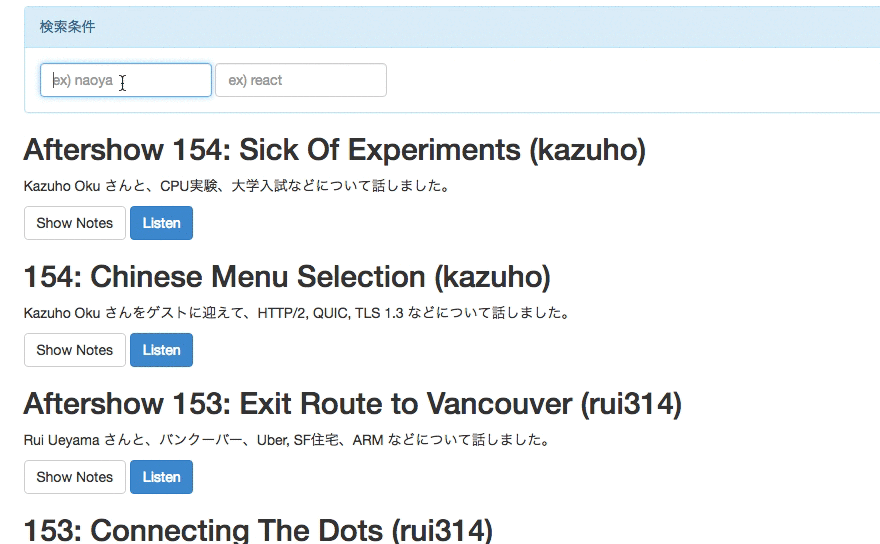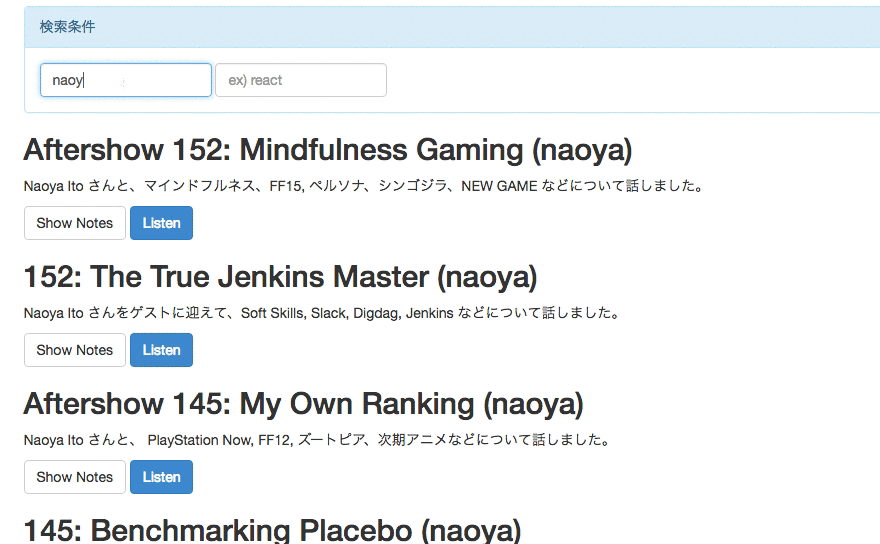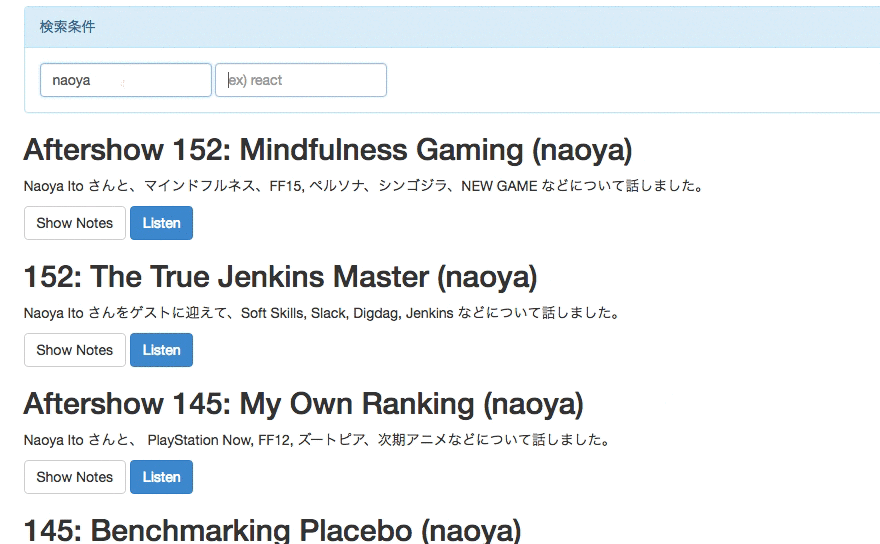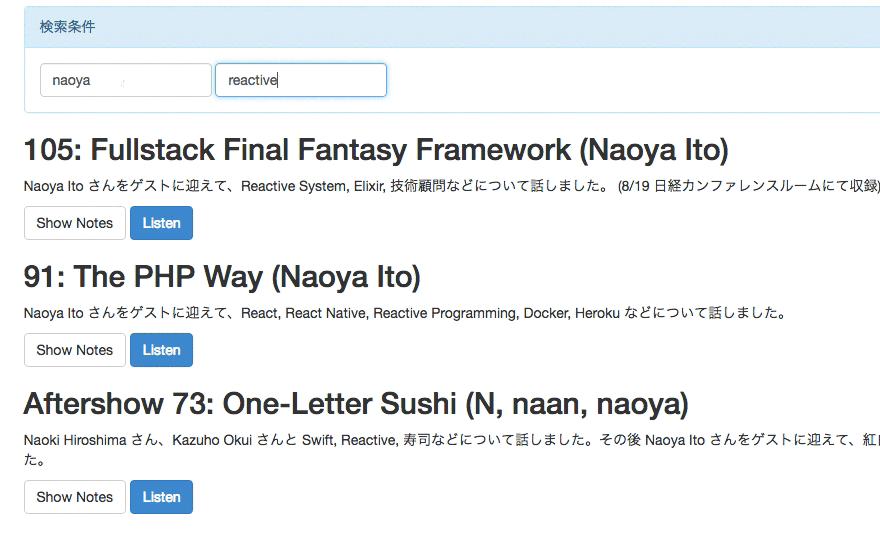
rebuild.fmのエピソード検索ができるwebサイトを作った
はじめに
Rails5.1の新機能を試すために、簡単なRailsアプリを作りました。 rebuild.fmのゲストとshownoteにフィルタリングをかけて検索できるようにしたものです。
heroku: https://shielded-river-53880.herokuapp.com/
idcf: http://rebuildfm-search.waterlow.tk/
リポジトリ以下です。
github: https://github.com/waterlow/rebuild-search
使っている技術等
とにかく今回はRails5.1を使ってみるのが目的でした。encrypted secretは、普通に本番運用でも使える物だと思いました。ただherokuでは必要なさそうなのと、本番とドッグフーディング環境等でconfig/secrets.yml.keyを分けたい場合に少し考えないといけません。
そちらへの解も考えていたので、今度個別の記事にします。
webpackerには深入りしてはいませんが、問題なく動いていそう…。 compression-webpack-pluginで圧縮した結果、chromeでエラーが起こっていたので圧縮しないようにしました。 https://github.com/waterlow/rebuild-search/commit/e34c52569b52dbdb88945ddaa16a5e621cbfccd9
herokuでもvpcでも共通で、かつスタンダードなスタックにしたかったのでpostgresqlを考えていましたが、centos&itamaeでのインストールが上手く行かずに断念してしまいました。ただ、今後移行する予定です。
vpsでサービス立ち上げ、デプロイ等までちゃんとやったことがなかったのでいい勉強になりました!
今後
テスト、ci、自動デプロイを整備して、ストレスなく開発できるようにする。
【LT】Railsのyaml、巨大になる前になんとかしようという内容で発表してきました!
反応
heroku使ってると環境変数だから問題は起きないかな。そこまでアプリが膨大になってないってのもあるか #startup_rails
— Kiminari Homma (@kimihom) March 6, 2017
settings.yml って要はグローバル変数と同じなので、可能な限り Model とかに定数で置いておいて、どうしてもアプリ全体で必要なものがあったら yml にするぐらいがちょうど良いと思う #startup_rails
— 神速@リリカルエンジニア (@sinsoku_listy) March 6, 2017
EC2 Systems Managerで環境変数管理している人いるのだろうか。興味ある #startup_rails
— alumys (@alumys) March 6, 2017
Heroku と ElasticBeanstalk 使ってるのでわりと変数問題は起きなかったかな〜!でも使ってないと思うと地獄になるのか。つらい。 #startup_rails
— まさたん😉マッスルファースト (@ma3tk) March 6, 2017
会話など
- 啓蒙や教育を怠らない
- 機能を絞る(コアドメインで勝負する)
Qiitaに初投稿!「hamlでタグを改行しない方法の整理」という記事を書きました
はじめに
タイトルの通り、Qiitaデビューした。前々から投稿したいと思っていたのだが、「ネタがない」「時間がない」などの言い訳をしつつ渋っていましたが、この度初投稿しました。
なんでこの記事を書いたのか
以前働いていたところでは、デザインはデザイナーがhtml, cssまで書き、エンジニアはhamlで実装しているような形でした。 そこではしばしば、デザイナーの書いたhtmlと、hamlで書いて出力されるhtmlが微妙に違うということがしばしばありました。 その原因の1つが、hamlの強制改行によるものでした。
Railsエンジニア1年目の自分は、そもそもhtmlを直接書かないこと、hamlというものがあること、インデントがちょっとずれるだけでエラーでhtmlをrenderできないことなど四苦八苦。改行を操作する方法があるということにたどり着いたのはだいぶ後でした。
そこで、「haml 改行しない」でぐぐると、シンプルな記事がでてくるようになるといいなという思いからこの記事を書きました。
「ワニが改行を食べる」イメージ
答えはいたってシンプルで、> or <の「口が開いている方の改行」を消すという覚え方が良さそうです。 出典は公式ドキュメントです
まとめ
Qiita初投稿を終えて、だいぶハードルが低くなったので、今後も投稿していく